11.03.2026: Die Systeme sind integriert. Die Schnittstellen dokumentiert. Der Data Lake ist aufgebaut. AI ist aktiviert. Und trotzdem entstehen Entscheidungen weiterhin in Silos.
Jede Anwendung optimiert ihren eigenen Bereich. Jede AI interpretiert Daten aus ihrer Perspektive.
Agenten sprechen miteinander – doch die Bedeutung bleibt fragmentiert.
Im ersten Beitrag haben wir gezeigt, warum Entscheidungsfähigkeit eine Architekturfrage ist.
Dieser Beitrag zeigt, wie eine solche Architektur konkret aussieht – und warum sie mehr braucht als Agent-to-Agent-Kommunikation.
Die Realität heutiger Enterprise-Architekturen
Über Jahre hinweg wurden Systeme sorgfältig eingeführt und integriert.
ERP.
CRM.
Commerce.
PIM.
Marketing.
Schnittstellen wurden gebaut. Prozesse abgestimmt. Datenflüsse definiert.
Dann kam der Data Lake hinzu.
Später ein Hyperscaler.
Und schließlich brachte jeder Hersteller eigene AI-Funktionen mit.
Das Ergebnis sind häufig Architekturen, in denen:
- Jedes System eigene AI-Funktionen besitzt
- Jede AI lokal optimiert
- Daten systemnah interpretiert werden
- Agenten direkt miteinander kommunizieren
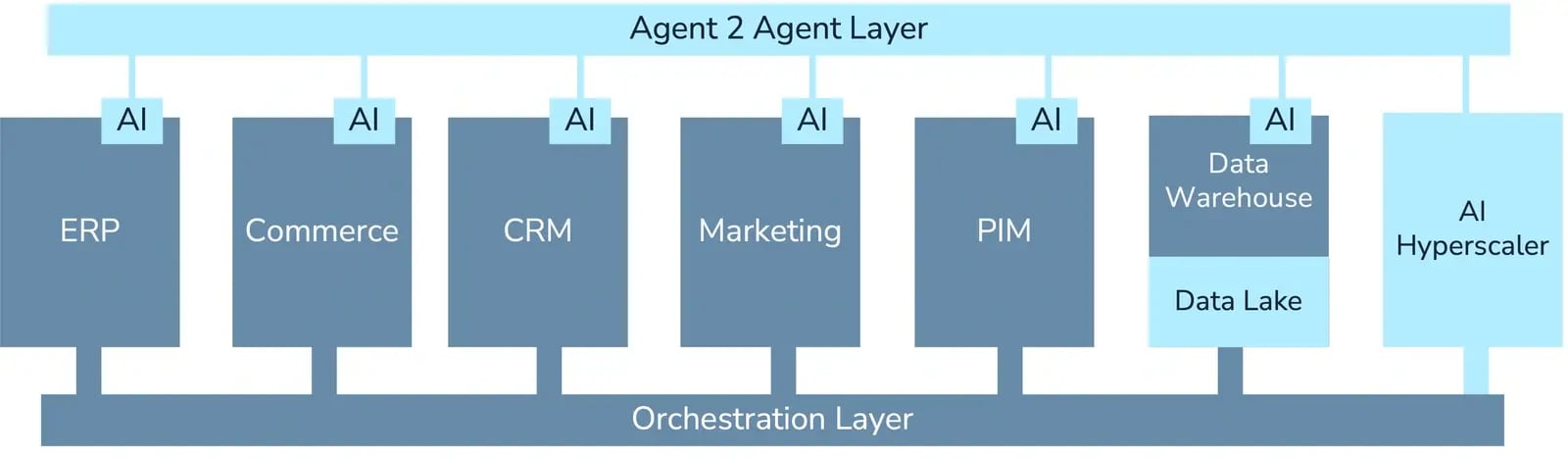
Aktuelle Architekturen skalieren AI innerhalb einzelner Systeme und nicht unternehmensweite Entscheidungslogik.
Wo das Problem wirklich liegt
Es geht nicht darum, dass es keine Definitionen gibt.
Im ERP existiert ein Deckungsbeitrag.
Im CRM gibt es Kundenzufriedenheit.
Im Marketing-System Engagement Scores.
Die Frage ist:
Welcher Wert gilt unternehmensweit?
Welche Berechnung ist führend?
Welche Interpretation ist maßgeblich?
Solange diese Deutungshoheit systemgebunden bleibt, bleibt auch Entscheidungsfähigkeit fragmentiert.
Agenten übernehmen diese Logik.
Oder interpretieren sie nach eigenen Maßstäben.
AI skaliert dann nicht unternehmensweite Entscheidungsqualität –
sondern lokale Interpretation.
Lokale AI ist wichtig – aber nicht ausreichend
Systemnahe AI bringt echten Mehrwert.
Im Customer Service generiert sie Antworten.
Im PIM extrahiert sie strukturierte Produktdaten.
Im Marketing erstellt sie Inhalte.
Das steigert Effizienz.
Doch Enterprise-Entscheidungen entstehen systemübergreifend.
Und genau hier beginnt die Rolle des Decision Ready Data Layers.
Die Entscheidungsarchitektur in drei Ebenen
Eine belastbare Entscheidungsarchitektur besteht aus:
- Operativen Systemen
ERP, CRM, Commerce, PIM - Decision Ready Data Layer
Semantik, Governance, Kontext - Interaction Layer
Dashboards, Apps, AI-Agenten, Conversational Interfaces
Der Decision Layer verbindet operative Systeme mit der Interaktionsebene.
Nicht das ERP spricht direkt mit dem Agenten.
Nicht das CRM interpretiert isoliert.
Sondern alle greifen auf dieselbe semantische Grundlage zu.
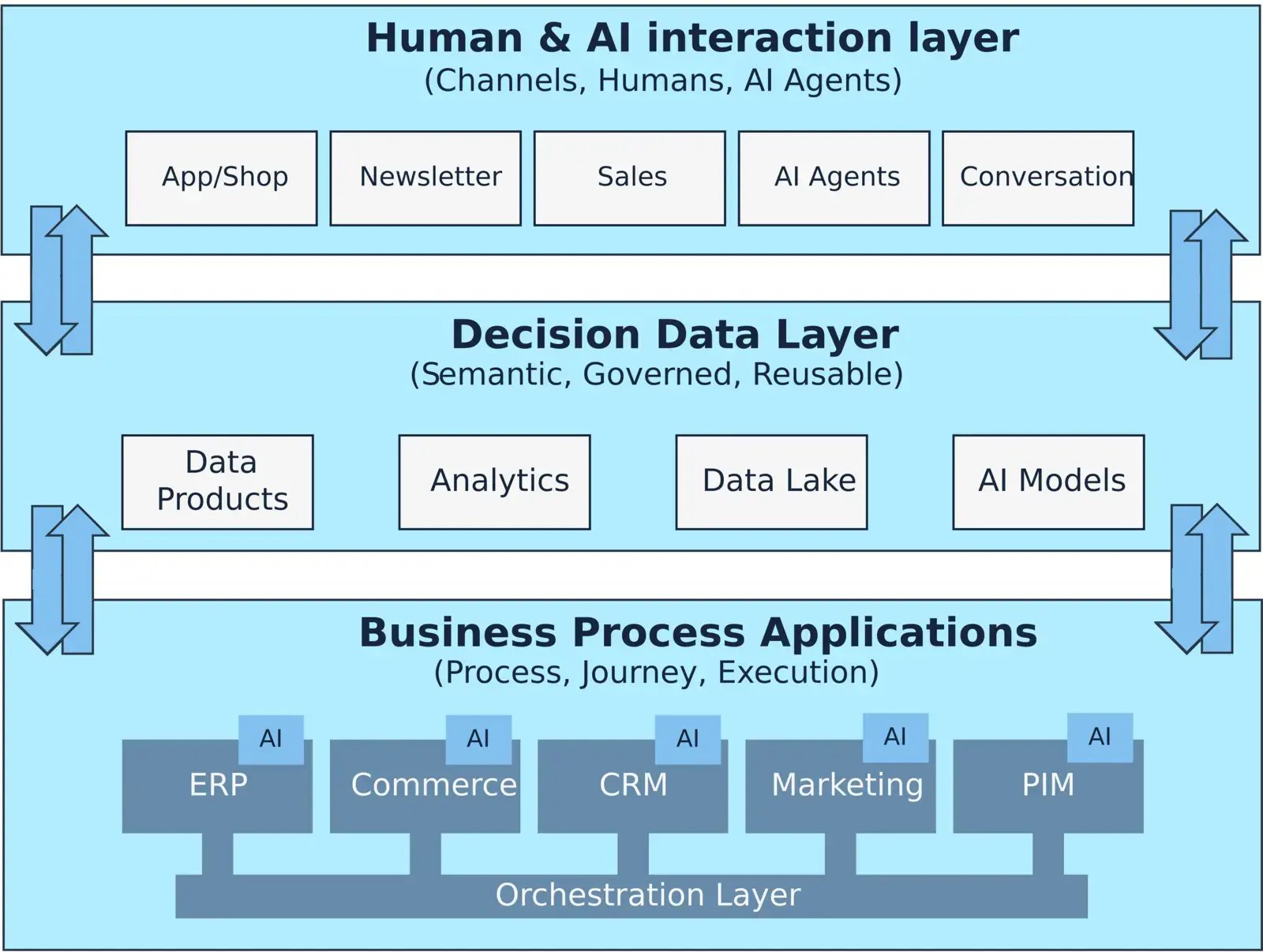
Ein Decision Ready Data Layer verbindet Systeme, Analytics und AI über eine gemeinsame semantische Grundlage.
Was ein Decision Ready Data Layer technisch wirklich ist
Er ist keine weitere Anwendung.
Er ersetzt keine Kernsysteme.
Er ist eine semantische Entscheidungsschicht.
Seine Aufgabe ist nicht primär Speicherung, sondern Interpretation.
Er definiert unternehmensweit:
- Geschäftsobjekte
- Hierarchien
- Ereignisse
- Berechnungslogiken
Er trennt Datenhaltung von Deutungshoheit.
Integration über Systemgrenzen hinweg
Enterprise-Landschaften bestehen aus ERP- und CRM-Systemen unterschiedlichster Hersteller.
Integration erfolgt über:
- API-basierte Schnittstellen
- Standardisierte Protokolle
- Out-of-the-box-Konnektoren
Architekturentscheidungen hängen ab von:
- Wie wichtig ist nahezu Echtzeit?
- Gibt es direkten Zugriff auf Quellsysteme?
- Ist Replikation sinnvoll, um Abhängigkeiten zu reduzieren?
Es gibt kein Dogma.
Es gibt Architekturprinzipien.
Strukturierte und unstrukturierte Daten
Ein Decision Ready Data Layer kann strukturierte und unstrukturierte Daten berücksichtigen.
Strukturierte Daten liefern Kennzahlen.
Unstrukturierte Daten liefern Kontext.
Nicht alles muss repliziert werden.
Kontext kann referenziert werden.
So entstehen Entscheidungen auf Basis vollständiger Geschäftsinformation.
Abgrenzung zu klassischen Data-Warehouse-Ansätzen
Klassische Data Warehouses sind auf Reporting optimiert.
Batch. ETL. Strukturierte Daten.
Ein Decision Ready Data Layer verschiebt den Fokus:
Von Speicherung zu Bedeutung.
Von Tabellen zu Geschäftsobjekten.
Von Reporting zu Entscheidungslogik.
Von nächtlicher Verarbeitung zu nahezu Echtzeit.
Bestehende Systeme bleiben bestehen.
Ihre Rolle verändert sich.
Verfügbarkeit ohne neue Abhängigkeit
Fällt der Decision Layer aus, funktionieren die Kernprozesse im ERP, CRM oder Commerce weiterhin.
Er optimiert Entscheidungen.
Er ersetzt keine Transaktionen.
Das ist entscheidend für Enterprise-Architekturen.
Governance und Berechtigungen – kein Widerspruch
Eine gemeinsame semantische Grundlage bedeutet nicht, dass jeder alles sieht.
Rollenbasierte Berechtigungen bleiben bestehen.
Die Interpretation ist konsistent.
Der Zugriff ist kontrolliert.
Semantik sorgt für Einheitlichkeit.
Governance sorgt für Sicherheit.
Beides ist notwendig.
Fazit
Agent-to-Agent-Kommunikation verbindet Systeme.
Ein Decision Ready Data Layer verbindet Bedeutung.
Lokale AI steigert Effizienz.
Eine gemeinsame semantische Architektur ermöglicht echte Enterprise-Entscheidungen.
Erst wenn Systeme integriert, Daten semantisch vereinheitlicht und nahezu in Echtzeit verfügbar sind, entsteht unternehmensweite Entscheidungsfähigkeit.
Nicht im Nachhinein.
Sondern im Moment der Entscheidung.